
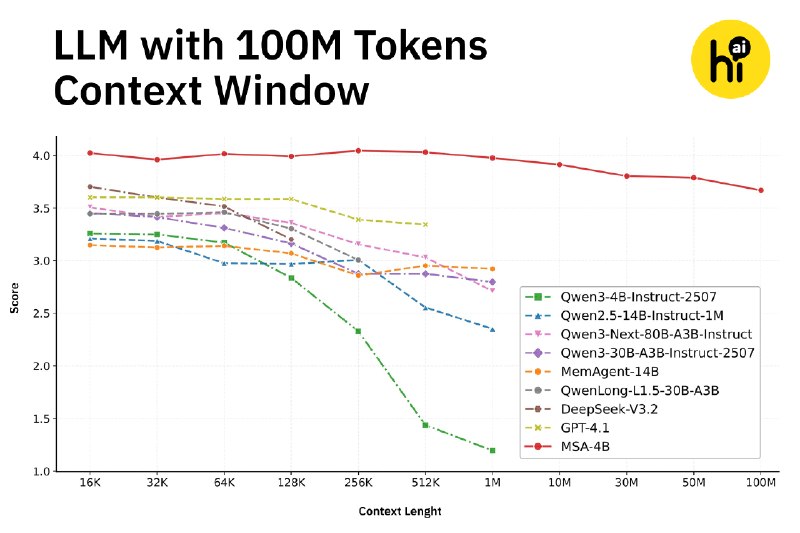
Researchers in China have developed a groundbreaking method to significantly increase the context capacity of large language models (LLMs). The startup Evermind has unveiled its innovative version of the transformer attention mechanism, termed Memory Sparse Attention (MSA). This new approach enables artificial intelligence models to handle contexts comprising hundreds of millions of tokens while maintaining nearly the same performance level. Currently, the most advanced AI models can only manage up to 1 million tokens.
So, how does this technology function? Traditional transformers analyze every preceding token for each input to provide a response, leading to exponential increases in computational demands as the context lengthens. In contrast, MSA does not review the entire context with each request. Instead, it employs a specialized router to extract only the pertinent information from the ongoing conversation. Furthermore, this architecture processes each document individually rather than merging everything into a single linear token stream, as is typical with standard transformers. This approach alleviates the problem of total context length since the model effectively "locates the right book on the right shelf" for each query.
For evaluation purposes, the developers adapted the Qwen3-4B model to integrate this new architecture. The resulting MSA-4B model not only excelled in attention benchmarks compared to other models but also demonstrated its proficiency even with a context of up to 100 million tokens.
While the existing limit of one million tokens suffices for casual interactions with AI, the MSA method could revolutionize the functionality of autonomous agents such as OpenClaw. This advancement allows them to operate more efficiently and accurately, eliminating the need to constantly compress user behavior and activities to conserve tokens.
Informational material. 18+.

